目錄
- F查詢
- Q查詢
- 事務(wù)
- 其他鮮為人知的操作
- Django ORM執(zhí)行原生SQL
- QuerySet方法大全
F查詢
在上面所有的例子中���,我們構(gòu)造的過濾器都只是將字段值與某個我們自己設(shè)定的常量做比較��。如果我們要對兩個字段的值做比較,那該怎么做呢�����?
Django 提供 F() 來做這樣的比較。F() 的實例可以在查詢中引用字段��,來比較同一個 model 實例中兩個不同字段的值。
示例1:
查詢出賣出數(shù)大于庫存數(shù)的商品
from django.db.models import F
ret1=models.Product.objects.filter(maichu__gt=F('kucun'))
print(ret1)
F可以幫我們?nèi)〉奖碇心硞€字段對應(yīng)的值來當作我的篩選條件����,而不是我認為自定義常量的條件了����,實現(xiàn)了動態(tài)比較的效果
Django 支持 F() 對象之間以及 F() 對象和常數(shù)之間的加減乘除和取模的操作��?���;诖丝梢詫Ρ碇械臄?shù)值類型進行數(shù)學(xué)運算
將每個商品的價格提高50塊
models.Product.objects.update(price=F('price')+50)
引申:
如果要修改char字段咋辦(千萬不能用上面對數(shù)值類型的操作?���。�?���!)����?
如:把所有書名后面加上'新款',(這個時候需要對字符串進行拼接Concat操作���,并且要加上拼接值Value)
from django.db.models.functions import Concat
from django.db.models import Value
ret3=models.Product.objects.update(name=Concat(F('name'),Value('新款')))
Concat表示進行字符串的拼接操作�,參數(shù)位置決定了拼接是在頭部拼接還是尾部拼接�����,Value里面是要新增的拼接值
Q查詢
filter()等方法中逗號隔開的條件是與的關(guān)系。如果你需要執(zhí)行更復(fù)雜的查詢(例如OR語句),你可以使用Q對象��。
示例1:
查詢 賣出數(shù)大于100 或者 價格小于100塊的
from django.db.models import Q
models.Product.objects.filter(Q(maichu__gt=100)|Q(price__lt=100))
對條件包裹一層Q時候�,filter即可支持交叉并的比較符
示例2:
查詢 庫存數(shù)是100 并且 賣出數(shù)不是0 的產(chǎn)品
models.Product.objects.filter(Q(kucun=100)~Q(maichu=0))
我們可以組合和|操作符以及使用括號進行分組來編寫任意復(fù)雜的Q對象。
同時���,Q對象可以使用~操作符取反,這允許組合正常的查詢和取反(NOT) 查詢���。
示例3:
查詢產(chǎn)品名包含新款, 并且?guī)齑鏀?shù)大于60的
models.Product.objects.filter(Q(kucun__gt=60), name__contains="新款")
查詢函數(shù)可以混合使用Q 對象和關(guān)鍵字參數(shù)���。所有提供給查詢函數(shù)的參數(shù)(關(guān)鍵字參數(shù)或Q對象)都將"AND”在一起。但是����,如果出現(xiàn)Q對象�����,它必須位于所有關(guān)鍵字參數(shù)的前面。
事務(wù)
事務(wù)的定義:將多個sql語句操作變成原子性操作�����,要么同時成功�,有一個失敗則里面回滾到原來的狀態(tài)�����,保證數(shù)據(jù)的完整性和一致性(NoSQL數(shù)據(jù)庫對于事務(wù)則是部分支持)
# 事務(wù)
# 買一本 跟老男孩學(xué)Linux 書
# 在數(shù)據(jù)庫層面要做的事兒
# 1. 創(chuàng)建一條訂單數(shù)據(jù)
# 2. 去產(chǎn)品表 將賣出數(shù)+1�����, 庫存數(shù)-1
from django.db.models import F
from django.db import transaction
# 開啟事務(wù)處理
try:
with transaction.atomic():
# 創(chuàng)建一條訂單數(shù)據(jù)
models.Order.objects.create(num="110110111", product_id=1, count=1)
# 能執(zhí)行成功
models.Product.objects.filter(id=1).update(kucun=F("kucun")-1, maichu=F("maichu")+1)
except Exception as e:
print(e)
其他鮮為人知的操作
Django ORM執(zhí)行原生SQL
條件假設(shè):就拿博客園舉例��,我們寫的博客并不是按照年月日來分檔,而是按照年月來分的�����,而我們的DateField時間格式是年月日形式,也就是說我們需要對從數(shù)據(jù)庫拿到的時間格式的數(shù)據(jù)再進行一次處理拿到我們想要的時間格式�����,這樣的需求��,Django是沒有給我們提供方法的,需要我們自己去寫處理語句了
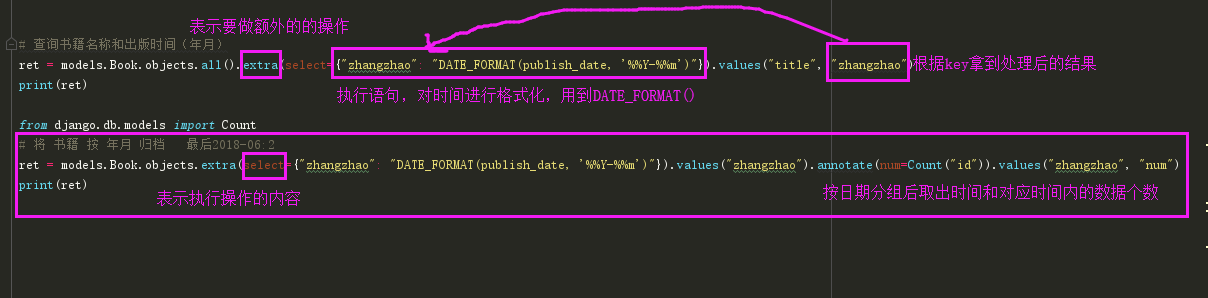
# extra
# 在QuerySet的基礎(chǔ)上繼續(xù)執(zhí)行子語句
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# select和select_params是一組,where和params是一組�,tables用來設(shè)置from哪個表
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
舉個例子:
models.UserInfo.objects.extra(
select={'newid':'select count(1) from app01_usertype where id>%s'},
select_params=[1,],
where = ['age>%s'],
params=[18,],
order_by=['-age'],
tables=['app01_usertype']
)
"""
select
app01_userinfo.id,
(select count(1) from app01_usertype where id>1) as newid
from app01_userinfo,app01_usertype
where
app01_userinfo.age > 18
order by
app01_userinfo.age desc
"""
# 執(zhí)行原生SQL
# 更高靈活度的方式執(zhí)行原生SQL語句
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [1])
# row = cursor.fetchone()
QuerySet方法大全
幾個比較重要的方法:
update()與save()的區(qū)別
兩者都是對數(shù)據(jù)的修改保存操作,但是save()函數(shù)是將數(shù)據(jù)列的全部數(shù)據(jù)項全部重新寫一遍�,而update()則是針對修改的項進行針對的更新效率高耗時少
所以以后對數(shù)據(jù)的修改保存用update()
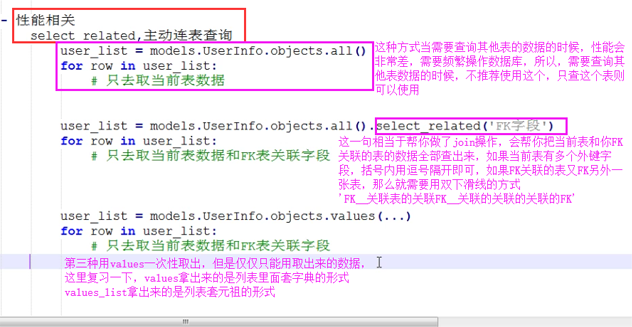
select_related和prefetch_related
def select_related(self, *fields)
性能相關(guān):表之間進行join連表操作,一次性獲取關(guān)聯(lián)的數(shù)據(jù)�。
總結(jié):
1. select_related主要針一對一和多對一關(guān)系進行優(yōu)化��。
2. select_related使用SQL的JOIN語句進行優(yōu)化,通過減少SQL查詢的次數(shù)來進行優(yōu)化�、提高性能。
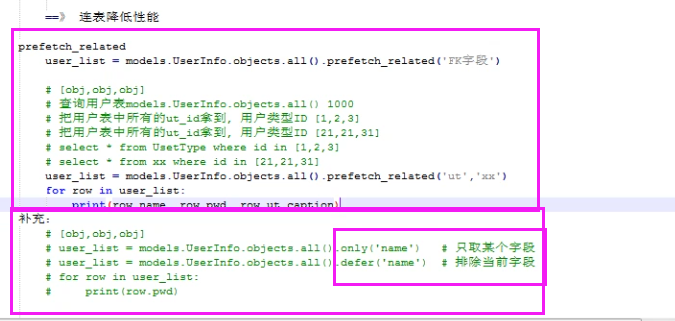
def prefetch_related(self, *lookups)
性能相關(guān):多表連表操作時速度會慢��,使用其執(zhí)行多次SQL查詢在Python代碼中實現(xiàn)連表操作�����。
總結(jié):
1. 對于多對多字段(ManyToManyField)和一對多字段�,可以使用prefetch_related()來進行優(yōu)化。
2. prefetch_related()的優(yōu)化方式是分別查詢每個表����,然后用Python處理他們之間的關(guān)系����。lated
 bulk_create
bulk_create
批量插入數(shù)據(jù)
要求:一次性插入多條數(shù)據(jù)
data = ["".join([str(random.randint(65, 99)) for i in range(4)]) for j in range(100)]
obj_list = [models.A(name=i) for i in data]
models.A.objects.bulk_create(obj_list)

QuerySet方法大全
##################################################################
# PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
##################################################################
def all(self)
# 獲取所有的數(shù)據(jù)對象
def filter(self, *args, **kwargs)
# 條件查詢
# 條件可以是:參數(shù),字典�����,Q
def exclude(self, *args, **kwargs)
# 條件查詢
# 條件可以是:參數(shù)��,字典�����,Q
def select_related(self, *fields)
性能相關(guān):表之間進行join連表操作�,一次性獲取關(guān)聯(lián)的數(shù)據(jù)���。
總結(jié):
1. select_related主要針一對一和多對一關(guān)系進行優(yōu)化�����。
2. select_related使用SQL的JOIN語句進行優(yōu)化�����,通過減少SQL查詢的次數(shù)來進行優(yōu)化�、提高性能��。
def prefetch_related(self, *lookups)
性能相關(guān):多表連表操作時速度會慢,使用其執(zhí)行多次SQL查詢在Python代碼中實現(xiàn)連表操作��。
總結(jié):
1. 對于多對多字段(ManyToManyField)和一對多字段����,可以使用prefetch_related()來進行優(yōu)化。
2. prefetch_related()的優(yōu)化方式是分別查詢每個表���,然后用Python處理他們之間的關(guān)系。
def annotate(self, *args, **kwargs)
# 用于實現(xiàn)聚合group by查詢
from django.db.models import Count, Avg, Max, Min, Sum
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
def distinct(self, *field_names)
# 用于distinct去重
models.UserInfo.objects.values('nid').distinct()
# select distinct nid from userinfo
注:只有在PostgreSQL中才能使用distinct進行去重
def order_by(self, *field_names)
# 用于排序
models.UserInfo.objects.all().order_by('-id','age')
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 構(gòu)造額外的查詢條件或者映射�����,如:子查詢
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by('-nid').reverse()
# 注:如果存在order_by����,reverse則是倒序,如果多個排序則一一倒序
def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列數(shù)據(jù)
def only(self, *fields):
#僅取某個表中的數(shù)據(jù)
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id')
def using(self, alias):
指定使用的數(shù)據(jù)庫�����,參數(shù)為別名(setting中的設(shè)置)
##################################################
# PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
##################################################
def raw(self, raw_query, params=None, translations=None, using=None):
# 執(zhí)行原生SQL
models.UserInfo.objects.raw('select * from userinfo')
# 如果SQL是其他表時�,必須將名字設(shè)置為當前UserInfo對象的主鍵列名
models.UserInfo.objects.raw('select id as nid from 其他表')
# 為原生SQL設(shè)置參數(shù)
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,])
# 將獲取的到列名轉(zhuǎn)換為指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map)
# 指定數(shù)據(jù)庫
models.UserInfo.objects.raw('select * from userinfo', using="default")
################### 原生SQL ###################
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
def values(self, *fields):
# 獲取每行數(shù)據(jù)為字典格式
def values_list(self, *fields, **kwargs):
# 獲取每行數(shù)據(jù)為元祖
def dates(self, field_name, kind, order='ASC'):
# 根據(jù)時間進行某一部分進行去重查找并截取指定內(nèi)容
# kind只能是:"year"(年), "month"(年-月), "day"(年-月-日)
# order只能是:"ASC" "DESC"
# 并獲取轉(zhuǎn)換后的時間
- year : 年-01-01
- month: 年-月-01
- day : 年-月-日
models.DatePlus.objects.dates('ctime','day','DESC')
def datetimes(self, field_name, kind, order='ASC', tzinfo=None):
# 根據(jù)時間進行某一部分進行去重查找并截取指定內(nèi)容�,將時間轉(zhuǎn)換為指定時區(qū)時間
# kind只能是 "year", "month", "day", "hour", "minute", "second"
# order只能是:"ASC" "DESC"
# tzinfo時區(qū)對象
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC)
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai'))
"""
pip3 install pytz
import pytz
pytz.all_timezones
pytz.timezone(‘Asia/Shanghai')
"""
def none(self):
# 空QuerySet對象
####################################
# METHODS THAT DO DATABASE QUERIES #
####################################
def aggregate(self, *args, **kwargs):
# 聚合函數(shù)�,獲取字典類型聚合結(jié)果
from django.db.models import Count, Avg, Max, Min, Sum
result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid'))
===> {'k': 3, 'n': 4}
def count(self):
# 獲取個數(shù)
def get(self, *args, **kwargs):
# 獲取單個對象
def create(self, **kwargs):
# 創(chuàng)建對象
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的個數(shù)
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)
def get_or_create(self, defaults=None, **kwargs):
# 如果存在,則獲取�����,否則����,創(chuàng)建
# defaults 指定創(chuàng)建時�,其他字段的值
obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2})
def update_or_create(self, defaults=None, **kwargs):
# 如果存在���,則更新,否則����,創(chuàng)建
# defaults 指定創(chuàng)建時或更新時的其他字段
obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1})
def first(self):
# 獲取第一個
def last(self):
# 獲取最后一個
def in_bulk(self, id_list=None):
# 根據(jù)主鍵ID進行查找
id_list = [11,21,31]
models.DDD.objects.in_bulk(id_list)
def delete(self):
# 刪除
def update(self, **kwargs):
# 更新
def exists(self):
# 是否有結(jié)果
到此這篇關(guān)于django中F與Q查詢的使用的文章就介紹到這了,更多相關(guān)django F與Q查詢內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- django框架F&Q 聚合與分組操作示例
- django 中的聚合函數(shù)��,分組函數(shù)��,F(xiàn) 查詢��,Q查詢
- Django ORM 聚合查詢和分組查詢實現(xiàn)詳解
- 模型聚合查詢\Q查詢\F查詢\分組查詢操作技巧解析
