概述
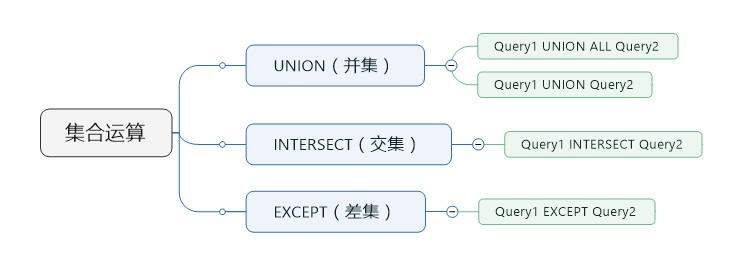
為什么使用集合運算:
在集合運算中比聯(lián)接查詢和EXISTS/NOT EXISTS更方便。
并集運算(UNION)
并集:兩個集合的并集是一個包含集合A和B中所有元素的集合。
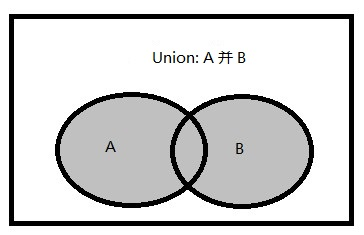
在T-SQL中�����。UNION集合運算可以將兩個輸入查詢的結(jié)果組合成一個結(jié)果集����。需要注意的是:如果一個行在任何一個輸入集合中出現(xiàn)�����,它也會在UNION運算的結(jié)果中出現(xiàn)�。T-SQL支持以下兩種選項:
(1)UNION ALL:不會刪除重復行
-- union allselect
country, region, city from hr.Employees
union all
select country, region, city from sales.Customers;
(2)UNION:會刪除重復行
-- union
select country, region from hr.Employees
union
select country, region from sales.Customers;
交集運算(INTERSECT)
交集:兩個集合(記為集合A和集合B)的交集是由既屬于A,也屬于B的所有元素組成的集合����。
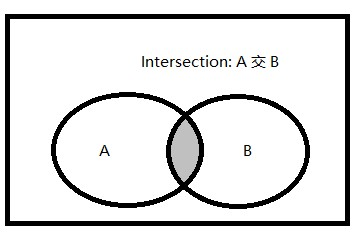
在T-SQL中,INTERSECT集合運算對兩個輸入查詢的結(jié)果取其交集���,只返回在兩個查詢結(jié)果集中都出現(xiàn)的行����。
INTERSECT集合運算在邏輯上會首先刪除兩個輸入集中的重復行�,然后返回只在兩個集合中中都出現(xiàn)的行。換句話說:如果一個行在兩個輸入集中都至少出現(xiàn)一次����,那么交集返回的結(jié)果中將包含這一行。
例如��,下面返回既是雇員地址��,又是客戶地址的不同地址:
-- intersect
select country, region, city from hr.Employees
intersect
select country, region, city from sales.Customers;
這里需要說的是����,集合運算對行進行比較時,認為兩個NULL值相等��,所以就返回該行記錄��。
差集運算(EXCEPT)
差集:兩個集合(記為集合A和集合B)的由屬于集合A�,但不屬于集合B的所有元素組成的集合。
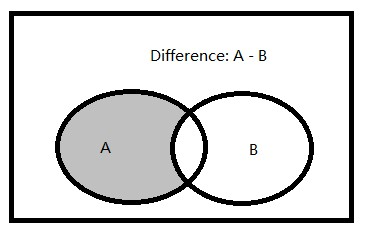
在T-SQL中�����,集合之差使用EXCEPT集合運算實現(xiàn)的����。它對兩個輸入查詢的結(jié)果集進行操作����,反會出現(xiàn)在第一個結(jié)果集中���,但不出現(xiàn)在第二個結(jié)果集中的所有行����。
EXCEPT結(jié)合運算在邏輯上首先刪除兩個輸入集中的重復行���,然后返回只在第一個集合中出現(xiàn)����,在第二個結(jié)果集中不出現(xiàn)的所有行�。換句話說:一個行能夠被返回,僅當這個行在第一個輸入的集合中至少出現(xiàn)過一次���,而且在第二個集合中一次也沒出現(xiàn)過���。
此外,相比UNION和INTERSECT�,兩個輸入集合的順序是會影響到最后返回結(jié)果的���。
例如,借助EXCEPT運算�,我們可以方便地實現(xiàn)屬于A但不屬于B的場景�����,下面返回屬于員工抵制�,但不屬于客戶地址的地址記錄:
-- except
select country, region, city from hr.Employees
except
select country, region, city from sales.Customers;
集合運算優(yōu)先級
SQL定義了集合運算之間的優(yōu)先級:INTERSECT最高,UNION和EXCEPT相等���。
換句話說:首先會計算INTERSECT�,然后按照從左至右的出現(xiàn)順序依次處理優(yōu)先級相同的運算��。
-- 集合運算的優(yōu)先級
select country, region, city from Production.Suppliers
except
select country, region, city from hr.Employees
intersect
select country, region, city from sales.Customers;
上面這段SQL代碼����,因為INTERSECT優(yōu)先級比EXCEPT高,所以首先進行INTERSECT交集運算��。因此��,這個查詢的含義是:返回沒有出現(xiàn)在員工地址和客戶地址交集中的供應商地址��。
集合運算的優(yōu)先級
1.INTERSECT>UNION=EXCEPT
2.首先計算INTERSECT,然后從左到右的出現(xiàn)順序依次處理優(yōu)先級的相同的運算。
3.可以使用圓括號控制集合運算的優(yōu)先級��,它具有最高的優(yōu)先級�。
在排序函數(shù)的OVER字句中使用ORDER BY ( SELECT 常量> )可以告訴SQL Server不必在意行的順序。
使用表表達式避開不支持的邏輯查詢處理
集合運算查詢本身并不持之除ORDER BY意外的其他邏輯查詢處理階段��,但可以通過表表達式來避開這一限制�����。
解決方案就是:首先根據(jù)包含集合運算的查詢定義一個表表達式���,然后在外部查詢中對表表達式應用任何需要的邏輯查詢處理�����。
(1)例如����,下面的查詢返回每個國家中不同的員工地址或客戶地址的數(shù)量:
select country, COUNT(*) as numlocations
from (select country, region, city from hr.Employees
union
select country, region, city from sales.Customers) as Ugroup by country;
(2)例如�����,下面的查詢返回由員工地址為3或5的員工最近處理過的兩個訂單:、
select empid,orderid,orderdate
from (select top (2) empid,orderid,orderdate
from sales.Orders
where empid=3
order by orderdate desc,orderid desc) as D1
union all
select empid,orderid,orderdate
from (select top (2) empid,orderid,orderdate
from sales.Orders
where empid=5
order by orderdate desc,orderid desc) as D2;
到此這篇關(guān)于sql server 交集,差集的用法詳解的文章就介紹到這了,更多相關(guān)sql server 交集,差集 內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家�����!
您可能感興趣的文章:- SQL語句的并集UNION 交集JOIN(內(nèi)連接���,外連接)等介紹
- MySQL實現(xiàn)差集(Minus)和交集(Intersect)測試報告
- MySQL 查詢結(jié)果取交集的實現(xiàn)方法
- SQLServer中求兩個字符串的交集
- mysql-joins具體用法說明
