互聯(lián)網(wǎng)中存在了大量的重復(fù)頁面�,據(jù)統(tǒng)計表明近似重復(fù)頁面的數(shù)量占據(jù)網(wǎng)站總數(shù)量的29%���,而完全重復(fù)頁面占據(jù)了22%��。這些重復(fù)的頁面對搜索引擎來說占據(jù)了很多的資源�����,因此搜索引擎對頁面的去重也是搜索引擎中很重要的一個算法����。因此今天就跟大家分析下搜索引擎頁面去重算法-I-Match算法����。
對于I-Match算法來說主要是根據(jù)大規(guī)模的文本集合進行統(tǒng)計����,對于文本中出現(xiàn)的所有單詞��,按照單詞的IDF(逆文本詞頻因子)來進行由高到低的排序�����,除去得分最高和得分最低的單詞�����,保留剩下的單詞最為特征詞典�。這一步驟主要是刪除文本中無關(guān)的關(guān)鍵詞�����,保留重要關(guān)鍵詞��。下面是I-Match流程示意圖:
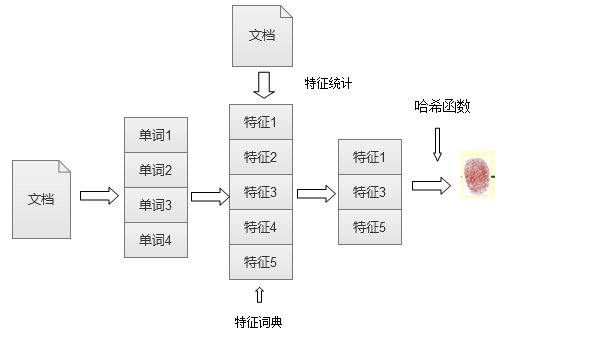
I-Match流程示意圖
獲得全局特征詞典之后��,對需要去重的頁面�,掃描下就能獲得該頁面上出現(xiàn)的所有單詞�,對于這些單詞根據(jù)特征詞典過濾:保留在特征詞典上出現(xiàn)的單詞�����,用來表達文檔的主要內(nèi)容����,刪除沒有在特征詞典中出現(xiàn)的內(nèi)容。提取出對應(yīng)的特征詞之后在利用哈希函數(shù)對特征詞匯進行哈希計算�����,獲得的數(shù)值就是該文檔的文本指紋����。
所有文檔都統(tǒng)計完之后如果想查看兩篇文檔是否重復(fù)只需要查看文檔的文本指紋是否近似,如果近似則表示兩篇文檔重復(fù)��。這樣的比對方式很直觀而且效率也很高����,去重效果比較明顯。
我們seo在做文章偽原創(chuàng)的時候經(jīng)常會把文章的詞語和段落調(diào)換位置��,以此想欺騙搜索引擎認為這是一篇原創(chuàng)的文章�����,但是I-Match對文檔之間的單詞順序并不敏感。如果兩篇文章中包含的單詞一樣僅僅是調(diào)換了單詞的位置����,那么I-Match算法還是將兩篇文章認為是重復(fù)文章。
但是這個算法還是有很多問題存在��。1�����,容易出現(xiàn)誤判�。尤其是面對短文本的時候�����,短文本本身單詞比較少�,經(jīng)過特征詞典過濾之后只保留很少的特證詞��,這樣容易把兩篇原本不重復(fù)的文檔誤認為重復(fù)���,這個對短文檔來說情況比較嚴重���。2.穩(wěn)定性不好,對文檔修改敏感��。假如對文檔A做出一點小修改后生成文檔B����,那么這個算法很可能判斷出兩篇文檔為不重復(fù)文檔。例如:我們在文檔A中加入一個單詞H���,生成文檔B。I-Match算法在進行計算的時候���,兩篇文章僅僅相差一個單詞H,如果單詞H不再特征詞典中那么兩篇文章的特證詞相同即判定為重復(fù)文檔�,但是會出現(xiàn)這種情況,單詞H出現(xiàn)在特征詞典中����,那么文本B比文檔A多出一個特征����,該算法很可能就會判定兩篇文檔不重復(fù)��。這就是I-Match最大的一個問題。
基于I-Match出現(xiàn)的這種問題����,有人對該算法進行了改進。原算法對文檔的改變非常敏感�����,主要是因為對單一特征詞典的過度依賴�����,改進后的I-Match就是減少對特征詞典的依賴性??梢圆捎枚鄠€特征詞典�����,只要每個特征詞典大體相近就可以忽略細小的差別�。
改變后的I-Match算法主要是:類似I-Match原始算法,形成一個特征詞典���,為了和其他詞典相區(qū)別可以成為主特征詞典�����;然后根據(jù)主特征詞典衍生出若干小的輔助特征詞典��。為了保證特征詞典的主體相同,可以從主特征詞典中隨機刪除若干詞典項然后生成一個新的特征詞典����,這個特征詞典就叫做輔助特征詞典,重復(fù)若干次數(shù)后就可以獲得若干輔助特征詞典�。當兩篇文檔進行對比的時候可以對主特征詞典和輔助特征詞典一起比對�����,只要保證每個特征詞典的大體內(nèi)容相同����,忽略細小差異就能判定文檔是否重復(fù)���。下圖是I-Match改進后的示意圖:
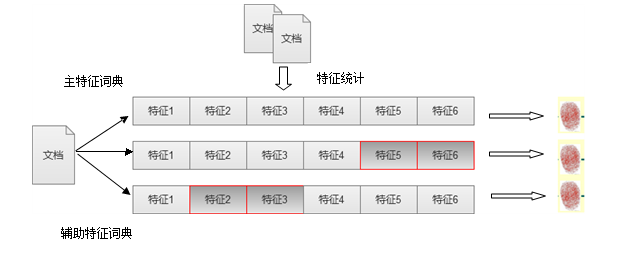
I-Match算法改進
上圖演示中有兩個輔助特征詞典�,主特征詞典拋棄了特征5和特征6形成輔助特征詞典1�����,主特征詞典拋棄了特征2和特征3形成了輔助特征詞典2�。并且根據(jù)三個特征詞典分別形成了文本指紋。如果兩篇文檔有兩個指紋信息相同那么即可判定兩篇文檔重復(fù)����。
改進后的I-Match算法大大提高了文檔去重的成功率����,增加了算法的穩(wěn)定性。
對SEO啟發(fā):傳統(tǒng)的偽原創(chuàng)文章�,對一篇文章進行簡單的修改�����,首尾做一些小的變動����,然后把中間段落調(diào)整順序����,這個對搜索引擎來說都是沒有意義的,還是可以判斷出兩篇文章是否重復(fù)�。因為我們對于文章的建設(shè)還是要原創(chuàng)����,或者對原文章進行比較大的改動,使兩篇文章的特征詞典發(fā)生改變�����。
詞語解釋:
IDF 逆文檔詞頻因子:衡量一個詞普遍重要度的衡量因子�,某一特定詞語的IDF�,可用總文件數(shù)目除以含有該詞語文檔數(shù)目���,將得到的商取對數(shù)得到����。

表示文檔總數(shù) n表示含有詞條k的文檔數(shù)量���。
本文由 http://www.youzu.com 供稿��,轉(zhuǎn)載請保留鏈接謝謝�����!
