1 問題描述
本文對建立好的復合索引進行排序,并取記錄中非索引字段,發(fā)現(xiàn)索引不生效�����,例如���,有如下表,DDL語句為:
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`emp_no`),
KEY `unique_birth_name` (`first_name`,`last_name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
復合索引為unique_birth_name (first_name,last_name) �。使用以下語句:
EXPLAIN SELECT
gender
FROM
employees
ORDER BY
first_name,
last_name

根據(jù)上圖:type:all 及 Extra:Using filesort 可得�,索引沒有生效��。
繼續(xù)進行試驗���,對查詢語句進一步改寫,加上一個范圍查找:
EXPLAIN SELECT
gender
FROM
employees
WHERE first_name > 'Leah'
ORDER BY
first_name,
last_name
執(zhí)行計劃顯示如下圖:

這里發(fā)現(xiàn)結(jié)果和第一次sql分析無異�����。繼續(xù)試驗�����。
改寫sql語句:
EXPLAIN SELECT
gender
FROM
employees
WHERE first_name > 'Tzvetan'
ORDER BY
first_name,
last_name

此時��,令人驚訝的是��,索引生效了。
2 問題分析
此時�,我們做一個大膽的猜測:
第一次進行sql分析時�����,因為第一次order by 后,得到的還是全表數(shù)據(jù)�����,如果根據(jù)復合索引中攜帶的主鍵查找每一個gender進行拼接�,自然很費資源和時間,mysql不會做如此蠢的事�����。不如直接進行全表掃描,把掃描到的每條數(shù)據(jù)和order by得到的臨時數(shù)據(jù)進行拼接�,從而得到需要的數(shù)據(jù)����。
為了驗證上述想法的正確性��,我們對三次sql進行分析�。
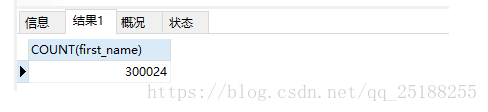
第一次sql根據(jù)復合索引得到的數(shù)據(jù)量為:300024���,為全表數(shù)據(jù)
SELECT
COUNT(first_name)
FROM
employees
ORDER BY
first_name,
last_name
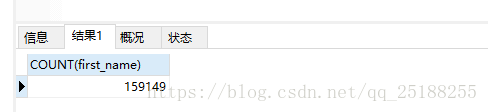
第二次改寫的sql根據(jù)復合索引得到的數(shù)據(jù)量為:159149 ���, 為全表數(shù)據(jù)量的1/2。
SELECT
COUNT(first_name)
FROM
employees
WHERE first_name > 'Leah'
ORDER BY
first_name,
last_name
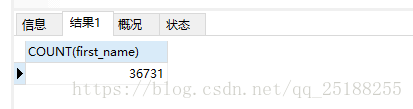
第三次改寫的sql根據(jù)復合索引得到的數(shù)據(jù)量為:36731�, 為全表數(shù)據(jù)量的1/10。
SELECT
COUNT(first_name)
FROM
employees
WHERE first_name > 'Tzvetan'
ORDER BY
first_name,
last_name
通過對比發(fā)現(xiàn)���,第二次改寫的sql根據(jù)復合索引得到的數(shù)據(jù)量是全表數(shù)據(jù)量的1/2�����。此時還沒有達到mysql使用索引進行二次查找的量級���。第三次改寫的sql根據(jù)復合索引得到的數(shù)據(jù)量是全表數(shù)據(jù)量的1/10�����,達到了mysql使用索引進行二次查找的量級,于是從執(zhí)行計劃上可以看到��,第三次改寫sql是走了索引的。
3 總結(jié)
mysql 是否根據(jù)首次索引條件查詢出的主鍵進行二次查找,也是要看查詢出來的數(shù)據(jù)量級,如果數(shù)據(jù)量接近全表數(shù)據(jù)量的話��,就會進行全表掃描���,否則根據(jù)第一次查詢出來的主鍵進行二次查詢�。
到此這篇關于MySql范圍查找時索引不生效問題原因分析的文章就介紹到這了,更多相關MySql范圍查找索引不生效內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- MySQL用B+樹作為索引結(jié)構(gòu)有什么好處
- 為什么MySQL數(shù)據(jù)庫索引選擇使用B+樹?
- MySQL 全文索引的原理與缺陷
- Mysql 5.6 "隱式轉(zhuǎn)換"導致的索引失效和數(shù)據(jù)不準確的問題
- MySQL索引失效的幾種情況詳析
- MySQL8.0中的降序索引
- MySQL 8.0 之索引跳躍掃描(Index Skip Scan)
- mysql性能優(yōu)化之索引優(yōu)化
- mysql 使用B+樹索引有哪些優(yōu)勢
