1、fit和fit_generator的區(qū)別
首先Keras中的fit()函數(shù)傳入的x_train和y_train是被完整的加載進內(nèi)存的,當然用起來很方便��,但是如果我們數(shù)據(jù)量很大��,那么是不可能將所有數(shù)據(jù)載入內(nèi)存的���,必將導(dǎo)致內(nèi)存泄漏�����,這時候我們可以用fit_generator函數(shù)來進行訓(xùn)練���。
下面是fit傳參的例子:
history = model.fit(x_train, y_train, epochs=10,batch_size=32,
validation_split=0.2)
這里需要給出epochs和batch_size,epoch是這個數(shù)據(jù)集要被輪多少次��,batch_size是指這個數(shù)據(jù)集被分成多少個batch進行處理��。
最后可以給出交叉驗證集的大小����,這里的0.2是指在訓(xùn)練集上占比20%。
fit_generator函數(shù)必須傳入一個生成器����,我們的訓(xùn)練數(shù)據(jù)也是通過生成器產(chǎn)生的,下面給出一個簡單的生成器函數(shù):
batch_size = 128
def generator():
while 1:
row = np.random.randint(0,len(x_train),size=batch_size)
x = np.zeros((batch_size,x_train.shape[-1]))
y = np.zeros((batch_size,))
x = x_train[row]
y = y_train[row]
yield x,y
這里的生成器函數(shù)我產(chǎn)生的是一個batch_size為128大小的數(shù)據(jù)����,這只是一個demo。如果我在生成器里沒有規(guī)定batch_size的大小����,就是每次產(chǎn)生一個數(shù)據(jù),那么在用fit_generator時候里面的參數(shù)steps_per_epoch是不一樣的�。
這里的坑我困惑了好久,雖然不是什么大問題
下面是fit_generator函數(shù)的傳參:
history = model.fit_generator(generator(),epochs=epochs,steps_per_epoch=len(x_train)//(batch_size*epochs))
2�����、batch_size和steps_per_epoch的區(qū)別
首先batch_size = 數(shù)據(jù)集大小/steps_per_epoch的,如果我們在生成函數(shù)里設(shè)置了batch_size的大小��,那么在fit_generator傳參的時候�����,,steps_per_epoch=len(x_train)//(batch_size*epochs)
我得完整demo代碼:
from keras.datasets import imdb
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras import layers
import numpy as np
import random
from sklearn.metrics import f1_score,accuracy_score
max_features = 10000
maxlen = 500
batch_size = 32
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
x_train = pad_sequences(x_train,maxlen=maxlen)
x_test = pad_sequences(x_test,maxlen=maxlen)
def generator():
while 1:
row = np.random.randint(0,len(x_train),size=batch_size)
x = np.zeros((batch_size,x_train.shape[-1]))
y = np.zeros((batch_size,))
x = x_train[row]
y = y_train[row]
yield x,y
# generator()
model = Sequential()
model.add(layers.Embedding(max_features,32,input_length=maxlen))
model.add(layers.GRU(64,return_sequences=True))
model.add(layers.GRU(32))
# model.add(layers.Flatten())
# model.add(layers.Dense(32,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])
print(model.summary())
# history = model.fit(x_train, y_train, epochs=1,batch_size=32, validation_split=0.2)
history = model.fit_generator(generator(),epochs=1,steps_per_epoch=len(x_train)//(batch_size))
print(model.evaluate(x_test,y_test))
y = model.predict_classes(x_test)
print(accuracy_score(y_test,y))
補充:model.fit_generator()詳細解讀
如下所示:
from keras import models
model = models.Sequential()
首先
利用keras���,搭建順序模型��,具體搭建步驟省略�。完成搭建后�,我們需要將數(shù)據(jù)送入模型進行訓(xùn)練,送入數(shù)據(jù)的方式有很多種�����,models.fit_generator()是其中一種方式����。
具體說,model.fit_generator()是利用生成器�,分批次向模型送入數(shù)據(jù)的方式���,可以有效節(jié)省單次內(nèi)存的消耗。
具體函數(shù)形式如下:
fit_generator(self, generator, steps_per_epoch, epochs=1, verbose=1, \
callbacks=None, validation_data=None, validation_steps=None,\
class_weight=None, max_q_size=10, workers=1, pickle_safe=False, initial_epoch=0)
參數(shù)解釋:
generator:一般是一個生成器函數(shù)��;
steps_per_epochs:是指在每個epoch中生成器執(zhí)行生成數(shù)據(jù)的次數(shù)�,若設(shè)定steps_per_epochs=100,這情況如下圖所示����;
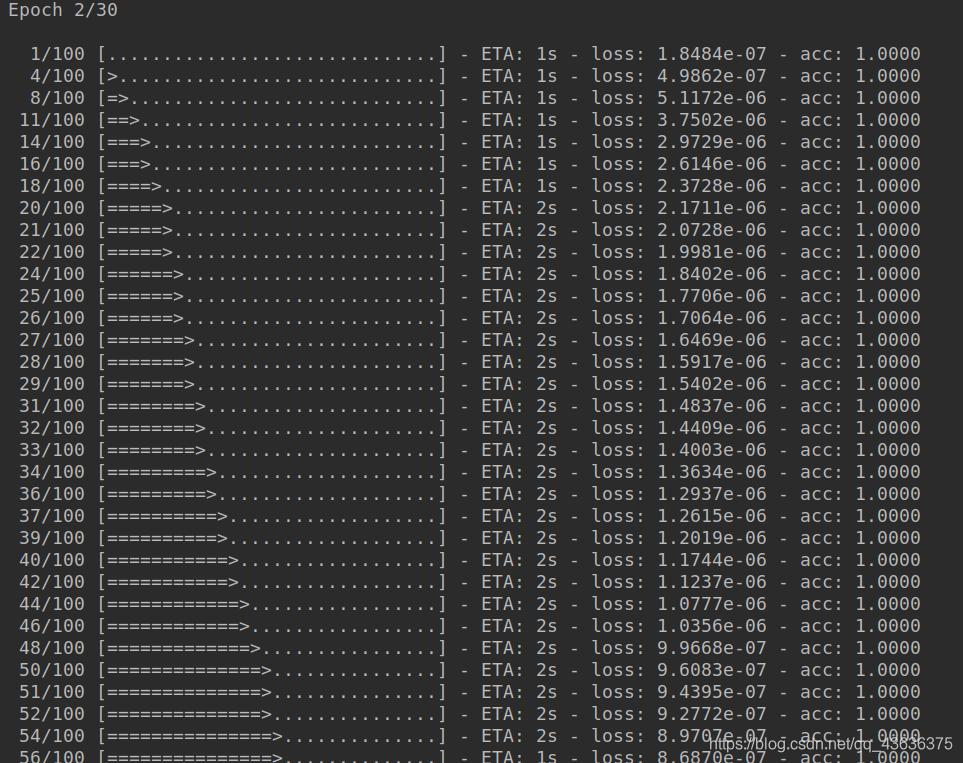
epochs:指訓(xùn)練過程中需要迭代的次數(shù);
verbose:默認值為1����,是指在訓(xùn)練過程中日志的顯示模式,取 1 時表示“進度條模式”���,取2時表示“每輪一行”�����,取0時表示“安靜模式”�;
validation_data, validation_steps指驗證集的情況���,使用方式和generator, steps_per_epoch相同�����;
models.fit_generator()會返回一個history對象���,history.history 屬性記錄訓(xùn)練過程中���,連續(xù) epoch 訓(xùn)練損失和評估值,以及驗證集損失和評估值����,可以通過以下方式調(diào)取這些值!
acc = history.history["acc"]
val_acc = history.history["val_acc"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
以上為個人經(jīng)驗��,希望能給大家一個參考��,也希望大家多多支持腳本之家�。
您可能感興趣的文章:- keras修改backend的簡單方法
- keras的get_value運行越來越慢的解決方案
- 基于keras中訓(xùn)練數(shù)據(jù)的幾種方式對比(fit和fit_generator)
- Keras保存模型并載入模型繼續(xù)訓(xùn)練的實現(xiàn)
- TensorFlow2.0使用keras訓(xùn)練模型的實現(xiàn)
- tensorflow2.0教程之Keras快速入門
- 淺析關(guān)于Keras的安裝(pycharm)和初步理解
- 基于Keras的擴展性使用
