目錄
- 一、前言
- 二��、數(shù)據(jù)爬取
- 三���、數(shù)據(jù)清洗
- 四�����、數(shù)據(jù)可視化
一�、前言
本文就從數(shù)據(jù)爬取��、數(shù)據(jù)清洗、數(shù)據(jù)可視化�����,這三個方面入手�,但你簡單完成一個小型的數(shù)據(jù)分析項目,讓你對知識能夠有一個綜合的運用����。
整個思路如下:
- 爬取網(wǎng)頁:https://www.jd.com/
- 爬取說明: 基于京東網(wǎng)站,我們搜索網(wǎng)站“粽子”數(shù)據(jù)�,大概有100頁。我們爬取的字段���,既有一級頁面的相關(guān)信息��,還有二級頁面的部分信息�����;
- 爬取思路: 先針對某一頁數(shù)據(jù)的一級頁面做一個解析�����,然后再進行二級頁面做一個解析�����,最后再進行翻頁操作��;
- 爬取字段: 分別是粽子的名稱(標題)�����、價格�、品牌(店鋪)、類別(口味)���;
- 使用工具: requests+lxml+pandas+time+re+pyecharts
- 網(wǎng)站解析方式: xpath
最終的效果如下:
二����、數(shù)據(jù)爬取
京東網(wǎng)站��,一般是動態(tài)加載的����,也就是說�,采用一般方式只能爬取到某個頁面的前30個數(shù)據(jù)(一個頁面一共60個數(shù)據(jù))。
基于本文,我僅用最基本的方法��,爬取了每個頁面的前30條數(shù)據(jù)(如果大家有興趣�����,可以自行下去爬取所有的數(shù)據(jù))�����。
那么�,本文究竟爬取了哪些字段呢?我給大家做一個展示��,大家有興趣��,可以爬取更多的字段���,做更為詳細的分析���。

下面為大家展示爬蟲代碼:
import pandas as pd
import requests
from lxml import etree
import chardet
import time
import re
def get_CI(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; X64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
rqg = requests.get(url,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 價格
p_price = html.xpath('//div/div[@class="p-price"]/strong/i/text()')
# 名稱
p_name = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/em')
p_name = [str(p_name[i].xpath('string(.)')) for i in range(len(p_name))]
# 深層url
deep_ur1 = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/@href')
deep_url = ["http:" + i for i in deep_ur1]
# 從這里開始,我們獲取“二級頁面”的信息
brands_list = []
kinds_list = []
for i in deep_url:
rqg = requests.get(i,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 品牌
brands = html.xpath('//div/div[@class="ETab"]//ul[@id="parameter-brand"]/li/@title')
brands_list.append(brands)
# 類別
kinds = re.findall('>類別:(.*?)/li>',rqg.text)
kinds_list.append(kinds)
data = pd.DataFrame({'名稱':p_name,'價格':p_price,'品牌':brands_list,'類別':kinds_list})
return(data)
x = "https://search.jd.com/Search?keyword=%E7%B2%BD%E5%AD%90qrst=1wq=%E7%B2%BD%E5%AD%90stock=1page="
url_list = [x + str(i) for i in range(1,200,2)]
res = pd.DataFrame(columns=['名稱','價格','品牌','類別'])
# 這里進行“翻頁”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存數(shù)據(jù)
res.to_csv('aliang.csv',encoding='utf_8_sig')
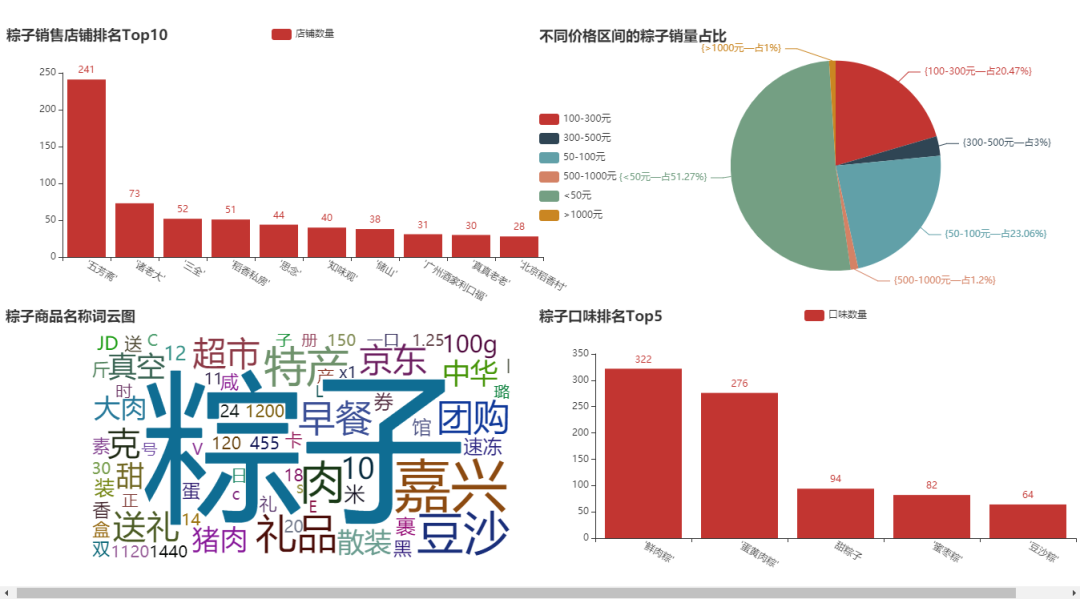
最終爬取到的數(shù)據(jù):

三����、數(shù)據(jù)清洗
從上圖可以看到���,整個數(shù)據(jù)算是很整齊的,不是特別亂�����,我們只做一些簡單的操作即可�����。
先使用pandas庫�,來讀取數(shù)據(jù)。
import pandas as pd
df = pd.read_excel("粽子.xlsx",index_col=False)
df.head()
結(jié)果如下:

我們分別針對 “品牌”�、“類別” 兩個字段,去掉中括號�。
df["品牌"] = df["品牌"].apply(lambda x: x[1:-1])
df["類別"] = df["類別"].apply(lambda x: x[1:-1])
df.head()
結(jié)果如下:
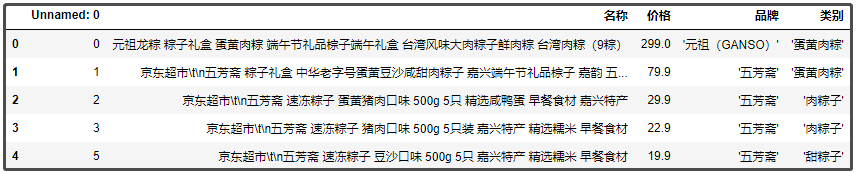
① 粽子品牌排名前10的店鋪
df["品牌"].value_counts()[:10]
結(jié)果如下:
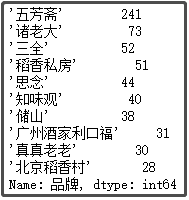
② 粽子口味排名前5的味道
def func1(x):
if x.find("甜") > 0:
return "甜粽子"
else:
return x
df["類別"] = df["類別"].apply(func1)
df["類別"].value_counts()[1:6]
結(jié)果如下:

③ 粽子售賣價格區(qū)間劃分
def price_range(x): # 按照我的購物習慣,劃分價格
if x = 50:
return '50元'
elif x = 100:
return '50-100元'
elif x = 300:
return '100-300元'
elif x = 500:
return '300-500元'
elif x = 1000:
return '500-1000元'
else:
return '>1000元'
df["價格區(qū)間"] = df["價格"].apply(price_range)
df["價格區(qū)間"].value_counts()
結(jié)果如下:

由于數(shù)據(jù)不是很多��,沒有很多字段�����,也就沒有很多亂數(shù)據(jù)�。因此���,這里也沒有做數(shù)據(jù)去重�����、缺失值填充等操作��。所以�,大家可以下去獲取更多字段,更多數(shù)據(jù)�����,用于數(shù)據(jù)分析��。
四���、數(shù)據(jù)可視化
俗話說:字不如表����,表不如圖�����。通過可視化分析��,我們可以將數(shù)據(jù)背后 “隱藏” 的信息,給展現(xiàn)出來�����。
拓展: 當然��,這里只是 “拋磚引玉”����,我并沒有獲取太多的數(shù)據(jù),也沒有獲取太多的字段��。這里給學習的朋友當一個作業(yè)題�,自己下去用更多的數(shù)據(jù)、更多的字段���,做更透徹的分析����。
在這里��,我們基于以下幾個問題���,做一個可視化展示���,分別是:
- ① 粽子銷售店鋪Top10柱形圖;
- ② 粽子口味排名Top5柱形圖�����;
- ③ 粽子銷售價格區(qū)間劃分餅圖����;
- ④ 粽子商品名稱詞云圖;
① 粽子銷售店鋪Top10柱形圖

結(jié)論分析:去年�����,我們分析了一些月餅的數(shù)據(jù)���,“五芳齋”���、“北京稻香村” 這幾個牌子記憶猶新,可謂是做月餅����、粽子的老店。像 “三全” 和 “思念”���,在我印象中一直以為它們只做水餃和湯圓��,粽子是否值得一試呢�?當然,這里還有一些新的牌子�����,像 “諸老大”����、“稻香私房” 等一些牌子,大家都可以下去搜索一下���。買東西����,就是要精挑細選����,品牌也重要。
② 粽子口味排名Top5柱形圖
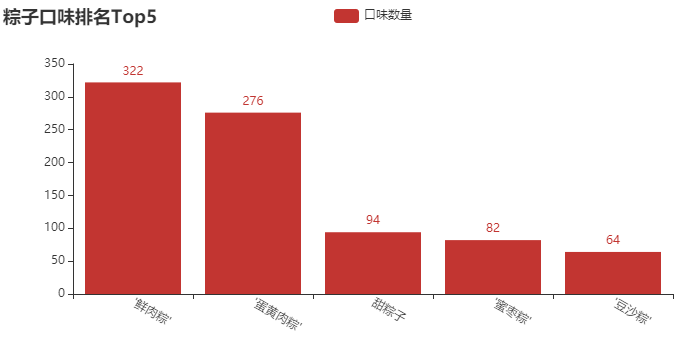
結(jié)論分析:在我印象中����,小時候一直吃的最多的就是 “甜粽子”�,直到我上了初中才知道��,粽子還可以有肉��?當然���,從圖中可以看出,賣 “鮮肉粽” 的店鋪還是居多����,畢竟這個送人,還是顯得高端�����、大氣一些��。這里還有一些口味���,像 “蜜棗粽”�����、“豆沙粽”�,我基本沒吃過。如果你送人���,你會送什么口味的呢�?
③ 粽子銷售價格區(qū)間劃分餅圖

結(jié)論分析:這里��,我故意把價格區(qū)間細分�����。這個餅圖也很符合實際�,畢竟每年就過一次端午節(jié),還是以薄利多銷為主��,接近80%的粽子���,售價都在100元以下��。當然����,還有一些中檔的粽子���,價格在100-300元�����。大于300元��,我覺得也沒有吃的必要���,反正我是不會花這么多錢去買粽子����。
④ 粽子商品名稱詞云圖

結(jié)論分析:從圖中�����,可以大致看出商家的賣點了�����。畢竟是節(jié)日�,“送禮”、“禮品” 體現(xiàn)了節(jié)日氛圍。“豬肉”��、“豆沙” 體現(xiàn)了粽子口味����。當然,它是否是 “早餐” 好選擇呢����?購買的話����,還支持 “團購” 哦。這些字眼���,多多少少都會各自吸引一部分人的眼球。
⑤ 圖形組合為大屏
到此這篇關(guān)于端午節(jié)將至,用Python將粽子數(shù)據(jù)可視化,看看網(wǎng)友喜歡哪種吧!的文章就介紹到這了,更多相關(guān)Python數(shù)據(jù)可視化內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家���!
您可能感興趣的文章:- Python爬蟲實戰(zhàn)之爬取京東商品數(shù)據(jù)并實實現(xiàn)數(shù)據(jù)可視化
- Python爬取股票信息,并可視化數(shù)據(jù)的示例
- Python爬取數(shù)據(jù)并實現(xiàn)可視化代碼解析
- python如何爬取網(wǎng)站數(shù)據(jù)并進行數(shù)據(jù)可視化
